Zabbix HA架构部署文档
1 zabbix运行条件
Server:
zabbix server需运行在LAMP(Linux+Apache+Mysql+PHP)环境下,对硬件要求低。
Agent:
目前已有的agent基本支持市面常见的OS,包含Linux、HPUX、Solaris、Sun、windows。
SNMP:
支持各类常见的网络设备。
1.2 zabbix功能
具备常见的商业监控软件所具备的功能(主机的性能监控、网络设备性能监控、数据库性能监控、FTP等通用协议监控、多种告警方式、详细的报表图表绘制)
支持自动发现网络设备和服务器,支持分布式,能集中展示、管理分布式的监控点,扩展性强,server提供通用接口,可以自己开发完善各类监控
1.3 优劣势
优点:
Ø开源,无软件成本投入
ØServer对设备性能要求低
Ø支持设备多
Ø支持分布式集中管理
Ø开放式接口,扩展性强
缺点:
Ø出现问题如需原厂支持需支付费用
Ø需在被监控主机上安装agent
-
zabbix配置文件
2.1 说明
Server:指安装zabbix服务的服务器(以下简称服务器端),是最重要的部份,主要安装在linux系统上(支持多种操作系统),采用mysql存储监控数据并使用apache+php的方式呈现。
Agent:指安装在被监控设备上的zabbix代理(以下简称代理),被监控设备上的数据由代理收集后统一上传到服务器端由服务器端收集、整理并呈现。
SNMP:也是agent的一种,指支持SNMP协议的设备(也可以是服务器),通过设定SNMP的参数将相关监控数据传送至服务器端(大部份的交换机、防火墙等网络设备都支持SNMP协议)。
IPMI:Agent的另一种方式,主要应用于设备的物理性能监控,例如设备的温度、风扇的转速等。
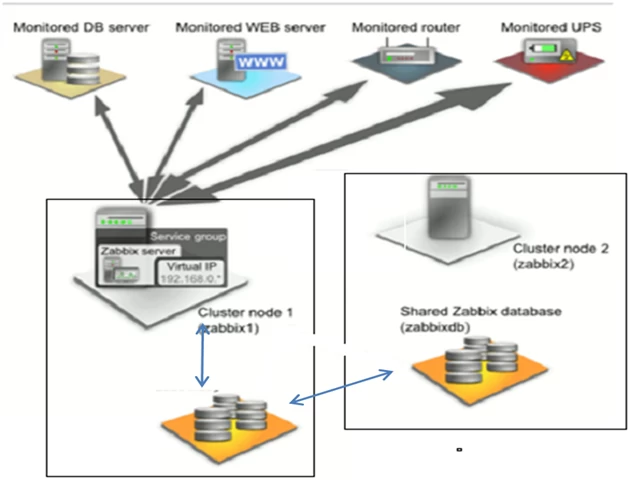
2.2 zabbix架构
zabbix支持多种网络方式下的监控,可通过分布式的方式部署和安装监控代理,整个架构如图所示。
-
系统规划
Ø系统环境:CentOS5.6 32bit、RHEL6.2 64bit
Ø每个节点服务器都有两块网卡,一块用作连接公用网络,另一块通过以太网交叉线连接两个节点,作为心跳监控,网络以及IP地址规划如表所示:
| 节点类型 | IP地址规划 | 主机名 | 类型 |
| 主用节点 | eth0:192.168.8.73/24 | server01 | Public IP |
| eth1:10.1.1.1/24 | private01 | private IP | |
| eth0:0:192.168.8.89 | 无 | Virtual IP | |
| 备用节点 | eth0:192.168.8.74/24 | server02 | Public IP |
| eth1:10.1.1.2/24 | private02 | private IP |
配置每个节点的/etc/hosts文件,保证两个节点内容一致,/etc/hosts文件内容如下:
192.168.8.73 server01
192.168.8.74 server02
10.1.1.1 private01
10.1.1.2 private02Ø系统拓扑:
-
zabbix server安装
Øzabbix版本:2.0.6
4.1 同步授时中心时间
Ø同步授时中心的时间,强制把系统时间写入CMOS。
ntpdate pool.ntp.org
clock -w
注意:这里说的是系统时间,是由linux操作系统维护的。在系统启动时,Linux操作系统将时间从CMOS中读到系统时间变量中,以后修改时间通过修改系统时间实现。为了保持系统时间与CMOS时间的一致性,Linux每隔一段时间会将系统时间写入CMOS。由于该同步是每隔一段时间(大约是11分钟)进行的,在我们执行date -s后,如果马上重起机器,修改时间就有可能没有被写入CMOS。
Ø每天凌晨、6点、12点和18点与授时中心同步时间,并将结果保存至/var/log/ntpdate.log文件中。
crontab -u root -e
添加:
0 0,6,12,18 * * * /usr/sbin/ntpdatepool.ntp.org >> /var/log/ntpdate.log
查询一下服务crond的情况:
chkconfig --list crond
查询一下用户root的cron的配置情况:
crontab -u root -l
Ø注意:linux下防火墙规则如果极严格的话可能会影响 ntpd 对时,打开 sport 123 即可(假设 OUTPUT链全 ACCEPT):
iptables -A INPUT -p udp --sport 123 -j ACCEPT
4.2 网卡服务配置
Ø停止NetworkManager服务,这样网卡就不受NetworkManage的控制。
/etc/init.d/NetworkManager stop
chkconfig NetworkManager off
4.3 建立LAMP环境
4.3.1 CentOS5.6
Ø安装rpmforge-release-0.5.3-1.el5.rf
rpm -ivh rpmforge-release-0.5.3-1.el5.rf.i386.rpm
备注:zabbix编译安装中的选项“--with-ssh2”对libssh2的版本要求为>=1.0.0,epel源的版本为0.18不符合需求,rpmforge源的版本为1.2.9符合需求。
注意:64位系统请安装此包
rpm -ivh rpmforge-release-0.5.3-1.el5.rf.x86_64.rpm
ØLAMP环境:
yum -y install httpd mysql-server php
Ø安装相关依赖包:
yum install -y gcc mysql-devel net-snmp-devel net-snmp-utils php-gd php-mysqlphp-common php-bcmath php-mbstring php-xml curl-devel iksemel* OpenIPMIOpenIPMI-devel fping libssh2 libssh2-devel unixODBC unixODBC-develmysql-connector-odbc openldap openldap-devel java java-devel
Ø配置http不随系统启动:
chkconfig httpd off
chkconfig mysqld on
注意:apache届时由heartbeat启动。
4.3.2 RHEL 6.2
Ø使用安装光盘建立本地yum源:
卸载已挂载的光盘:
umount /dev/sr0
挂载光盘并写入配置文件:
mount /dev/sr0 /media/
vi /etc/fstab
末尾添加:
/dev/sr0 /media iso9660 defaults 0 0创建yum配置文件:
vi /etc/yum.repos.d/rhel6.repo
添加:
[base]
name=base
baseurl=file:///media/
enabled=1
gpgcheck=0
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-redhat-releaseØ安装epel-release-6-8.noarch.rpm:
rpm -ivh epel-release-6-8.noarch.rpm
Ø导入key:
rpm --import /etc/pki/rpm-gpg/RPM-GPG-KEY-EPEL-6
Ø添加163上的CentOS6源:
wget -O /etc/yum.repos.d/CentOS6-Base-163.repohttp://mirrors.163.com/.help/CentOS6-Base-163.repo
Ø编辑CentOS6-Base-163.repo把文件里面的$releasever全部替换为6:
vi /etc/yum.repos.d/CentOS6-Base-163.repo
ØLAMP环境:
yum -y install httpd mysql-server php
Ø安装相关依赖包:
yum install -y gcc mysql-devel net-snmp-devel net-snmp-utils php-gd php-mysqlphp-common php-bcmath php-mbstring php-xml curl-devel iksemel* OpenIPMIOpenIPMI-devel fping libssh2 libssh2-devel unixODBC unixODBC-develmysql-connector-odbc openldap openldap-devel java java-devel
Ø配置http不随系统启动:
chkconfig httpd off
chkconfig mysqld on
注意:apache届时由pacemaker启动。
4.4 禁用SELINUX
setenforce 0
修改/etc/selinux/config文件中设置SELINUX=disabled
sed -i 's/SELINUX=enforcing/SELINUX=disabled/' /etc/selinux/config
备注:
设置SELinux 成为enforcing模式
setenforce 1
设置SELinux 成为permissive模式
setenforce 0
4.5 新建zabbix组和用户
/usr/sbin/groupadd zabbix
/usr/sbin/useradd -g zabbix zabbix
4.6 编译安装zabbix
4.6.1 编译安装
Ø下载解压zabbix:
wget http://sourceforge.net/projects/zabbix/files/ZABBIX%20Latest%20Stable/2.0.6/zabbix-2.0.6.tar.gz/download
tar zxvf zabbix-2.0.6.tar.gz
Ø编译安装:
cd /root/zabbix-2.0.6/
./configure --prefix=/usr/local/zabbix --enable-server --enable-agent --enable-proxy --with-mysql --enable-java --enable-ipv6 --with-net-snmp --with-libcurl --with-ldap --with-ssh2 --with-jabber --with-openipmi --with-unixodbc
make && make install
configure:error: Invalid NET-SNMP directory - unable to find net-snmp-config
编译安装zabbix时,配置时报以上错,导致检测系统环境不成功。提示unableto find net-snmp-config,说明缺少相关的依赖性。
这是因为,在linux中,大多数软件都是开源的,并且可以自由使用。因此在开发时可以用到其他的软件包时我们直接就拿来了,不用在花功夫去重新编写,这就造成了所谓的依赖性。
那么怎么解决该问题那?
解决办法一:
找出net-snmp-config属于哪个软件包,然后安装即可。
yum search net-snmp-config,发现net-snmp-config属于软件包net-snmp-devel,yum安装该软件包,解决该问题。
解决办法二:
在配置时,我们加上了--with-net-snmp这个选项,因此需要检查系统环境是否有该软件包支持。因此,在配置时,不要加上--with-net-snmp这个选项即不会报如下错误configure:error: Invalid NET-SNMP directory - unable to find net-snmp-config。
参考文献:zabbix中文文档http://www.linuxmr.com/zabbix2/
4.6.2 创建zabbix数据库
Ø开启mysql,修改mysql root密码为123456(实际使用环境中可自定义密码):
/etc/init.d/mysqld start
/usr/bin/mysqladmin -u root password 123456
Ø创建zabbix库,设置字符为utf8:
/usr/bin/mysql -uroot -p123456
create database zabbix character set utf8;
grant all privileges on zabbix.* to 'zabbix'@'192.168.8.89' identified by '123456';
grant all privileges on zabbix.* to 'zabbix'@'localhost' identified by '123456';
开启zabbix用户远程连接权限(可选):
grant all privileges on zabbix.* to 'zabbix'@'%' identified by '123456';
quit
备注:zabbix数据库可以和zabbix服务器分离,采用后端数据层的mysql服务器存储数据提高安全,本例因实体机仅有二台,故zabbix server和mysql server还在同一台物理机中。
注意:本例为heartbeat的VIP地址。(请按实际环境设置VIP地址):
Ø导入数据库:
cd /root/zabbix-2.0.6/database/mysql/
mysql -uzabbix -h 192.168.8.89 -p123456 zabbix < schema.sql
mysql -uzabbix -h 192.168.8.89 -p123456 zabbix < images.sql
mysql -uzabbix -h 192.168.8.89 -p123456 zabbix < data.sql4.6.3 复制配置文件到zabbix安装目录
cp -R /root/zabbix-2.0.6/conf/zabbix_agentd /usr/local/zabbix/etc/
cp /root/zabbix-2.0.6/conf/zabbix_agentd.win.conf /usr/local/zabbix/etc/
cp /root/zabbix-2.0.6/conf/zabbix_proxy.conf /usr/local/zabbix/etc/
Ø修改zabbix_server.conf配置文件数据库(mysql)相关部分:
vim /usr/local/zabbix/etc/zabbix_server.conf
修改以下内容:
DBUser=zabbix
DBPassword=123456
4.6.4 添加服务端口
vim /etc/services
在末尾追加以下内容:
#zabbix services
zabbix-agent 10050/tcp # Zabbix Agent
zabbix-agent 10050/udp # Zabbix Agent
zabbix-trapper 10051/tcp # Zabbix Trapper
zabbix-trapper 10051/udp # Zabbix Trapper
4.6.5 修改zabbix目录用户属性
chown -R zabbix.zabbix /usr/local/zabbix/
4.6.6 配置软连接
Ø为 zabbix 命令行操作文件做链接,方便系统可以找得到。
ln -s /usr/local/zabbix/bin/* /usr/bin/
ln -s /usr/local/zabbix/sbin/* /usr/sbin/
4.6.7 配置zabbix启动脚本
Ø拷贝zabbix启动脚本到/etc/init.d/下。
cp /root/zabbix-2.0.6/misc/init.d/fedora/core/zabbix_* /etc/init.d/
Ø修改zabbix启动脚本中程序目录的位置。
vim /etc/init.d/zabbix_server
修改:
BASEDIR=/usr/local/zabbix
vim /etc/init.d/zabbix_agentd
修改:
BASEDIR=/usr/local/zabbix
Ø添加可执行权限。
chmod +x /etc/init.d/zabbix_server
chmod +x /etc/init.d/zabbix_agentd
4.6.8 添加开机启动服务
chkconfig --add zabbix_server
chkconfig --add zabbix_agentd
chkconfig --level 345 zabbix_server off
chkconfig --level 345 zabbix_agentd on
注意:zabbix_server届时由heartbeat启动。
使用 chkconfig --list 检查一下:
chkconfig --list | grep zabbix
4.6.9 web相关配置
mkdir /var/www/html/zabbix
cp -a /root/zabbix-2.0.6/frontends/php/* /var/www/html/zabbix/
chown -R zabbix.zabbix /var/www/html/zabbix/
Ø对php配置文件做相应的调整(实际使用环境中可按需求更改,zabbix2.0.6运行的最低环境要求请参考下图):
vim /etc/php.ini
修改:
max_execution_time = 600
max_input_time = 600
memory_limit = 256M
post_max_size = 32M
upload_max_filesize = 16M
date.timezone = PRCphp.ini中的时区设置date.timezone = PRC
无意中发现 lnmp 默认的 php.ini 配置中有一行 date.timezone = PRC。PRC,People’s Republic of China,中华人民共和国,也就是日期使用中国的时区。
date.timezone 是 PHP 5.1 中新增加的配置文件参数,默认 date.timezone 是被注释掉的,也就是默认时区是 utc,lnmp 改为了 date.timezone = PRC,这样可以解决时间相差八小时的问题,看来 lnmp 的本土化工作做得不错。不过貌似这个参数一般都设成 Asia/Shanghai吧?在 PHP 官方文档上找了半天才找到 PRC 这个参数,它不在Asia这个分类中,而在Others,一般人都会在 Asia 里面找吧。
搜索了一下 PHP 源码,在 ext/date/lib/timezonemap.h 中看到如下代码
{ "cst", 0, 28800, "Asia/Chongqing" },
{ "cst", 0, 28800, "Asia/Chungking" },
{ "cst", 0, 28800, "Asia/Harbin" },
{ "cst", 0, 28800, "Asia/Kashgar" },
{ "cst", 0, 28800, "Asia/Macao" },
{ "cst", 0, 28800, "Asia/Macau" },
{ "cst", 0, 28800, "Asia/Shanghai" },
{ "cst", 0, 28800, "Asia/Taipei" },
{ "cst", 0, 28800, "Asia/Urumqi" },
{ "cst", 0, 28800, "PRC" },
{ "cst", 0, 28800, "ROC" },
对PHP 源码的时间部分没有什么研究,姑且认为这几个参数都表示 UTC+8 的东八区中国的北京时间吧。
当然,可以在 PHP 代码中调用 date_default_timezone_set 函数设置运行时的时区,这是常识,我就不多说了。
参考文献:http://demon.tw/software/php-date-timezone.html
Ø启动zabbixserver和agent。
/etc/init.d/zabbix_agentd start
/etc/init.d/zabbix_server start
Ø打开浏览器,输入http://IP/zabbix/,就会出现WEB界面安装向导,按向导提示完成zabbix安装。
默认:Next
默认:Next
输入Mysql数据库端口:3306,用户名:zabbix,密码:123456
注意:
l将localhost改为VIP地址。
l此处是zabbix连接mysql数据库时用到的用户名和密码,切勿混淆。
测试连接通过后→Next
默认:Next(实际使用环境中可按需求更改)
默认:Next
注意:如果出现提示文件zabbix.conf.php无法创建,则是zabbix目录无法写入,/var/www/html/zabbix的权限不为apache.apache。
解决方法一:点击“Download configuration file”,将下载的zabbix.conf.php文件上传到服务器的/var/www/html/zabbix/conf/zabbix.conf.php去然后点击“Retry”就不会有Fail了。
解决方法二:输入以下命令也可解决。
chown -R apache.apache /var/www/html/zabbix
点击“Finish”完成安装
输入用户名:admin,密码:zabbix
4.7 解决zabbix图中出现中文乱码
Ø设置zabbix的语言为中文时,图中的中文会变成方块,如下图所示:
这个问题是由于zabbix的web端没有中文字库,需要把中文字库加上即可。
1)在windows系统中的c:\windows\fonts目录中copy一个自己喜欢的字体文出来,如msyh.ttf(雅黑);
2)将copy出来的字体上传到zabbix server网站目录中的fonts目录下;
3)将zabbix server网站目录中的fonts目录里原来的“DejaVusSans.ttf”改名,例如为“DejaVusSans.ttf.bak”;
cd /var/www/html/zabbix/fonts
mv DejaVuSans.ttf /var/www/html/zabbix/fonts/DejaVuSans.ttf.bak
4)将上传上去的文件,例如“mysh.ttf”改为“DejaVusSans.ttf”;
mv msyh.ttf /var/www/html/zabbix/fonts/DejaVuSans.ttf
5)刷新页面后会发现原来乱码的地方OK了。
4.8 更改监控项类型
Ø监控项(items)默认为被动式,因双主配置使用vip,server端发起的请求包无法回到vip地址,故临时可用主动式的方式解决此问题。
4.9 防火墙设置
Øntp:
iptables -A INPUT -p udp --sport 123 -j ACCEPT
Øapache和mysql:
iptables -A INPUT -p tcp --dport 80 -j ACCEPT
iptables -A INPUT -p tcp --dport 3306 -j ACCEPT
Øzabbix server:
iptables -A INPUT -p tcp --dport 10050 -j ACCEPT
iptables -A INPUT -p tcp --dport 10051 -j ACCEPT
iptables -A INPUT -p udp --dport 10050 -j ACCEPT
iptables -A INPUT -p udp --dport 10051 -j ACCEPT
或
iptables -A INPUT -p tcp -s 客户端IP -m multiport --dports 10050,10051 -j ACCEPT
iptables -A INPUT -p udp -s 客户端IP -m multiport --dports 10050,10051 -j ACCEPT
-
mysql数据库双主同步配置说明
5.1 服务器A、B的ip地址
服务器A:10.1.1.1
服务器B:10.1.1.2
5.2 备份zabbix库
mysqldump -h localhost -u root -p123456 zabbix >zabbix.sql
5.3 分别在两台服务器上建立同步用户
Ø设置数据库同步帐户:
mysql -u root -p123456
服务器A:
grant replication slave,file on *.* to 'tongbu'@'10.1.1.2' identified by 'tongbu';
flush privileges;
服务器B:
grant replication slave,file on *.* to 'tongbu'@'10.1.1.1' identified by 'tongbu';
flush privileges;
Ø查看已建立的同步账户:
use mysql;
select user,host from user;
5.4 修改服务器的数据库配置文件/etc/my.cnf
Ø服务器A的my.cnf配置:
注意:server-id默认为1,一般主从同步中,主服务器server-id为1,双主同步原则上两台同步服务器server-id不同即可。
vi /etc/my.cnf
在user=mysql后添加:
log-bin=mysql-bin
relay-log=relay-bin
relay-log-index=relay-bin-index
server-id = 1
master-connect-retry=30
binlog-do-db=zabbix
replicate-do-db=zabbix
binlog-ignore-db=mysql
replicate-ignore-db=mysql
binlog-ignore-db=test
replicate-ignore-db=test
binlog-ignore-db=largedate
replicate-ignore-db=largedate
binlog-ignore-db=information_schema
replicate-ignore-db=information_schema
binlog-ignore-db=performance_schema
replicate-ignore-db=performance_schema
log-slave-updates
slave-skip-errors=all
lserver-id = 1 服务器ID号
lmaster-connect-retry=30 断点重试间隔为30秒
lbinlog-do-db=zabbix 表示同步zabbix数据库
lreplicate-do-db=zabbix 表示同步zabbix数据库
lbinlog-ignore-db=mysql 不同步mysql数据库
llog-slave-updates
在从服务器上将复制过来的更新操作写入二进制日志,从而可以得到完整的二进制日志,便于数据恢复和重现。
lslave-skip-errors=all
l跳过复制错误,该参数目前设置值为all,即跳过所有复制错误,实际使用时也可以缩小跳过错误的范围。
备注:binlog-ignore-db和replicate-ignore-db表示不需要同步的数据库,可以不设置(不设置时,mysql也只会同步binlog-do-db中设置的数据库),但是为了安全起见,建议设置该参数。yum安装的mysql实际只需要不同步mysql和test库即可,如果从官网下载rpm包安装mysql5.5则不同。
注意:很多案例会将同步账户设置在此配置文件中,个人不建议这样做。
Ø服务器B的my.cnf配置与服务器A一样,只需要将server-id改为2。
Ø重启服务器A和服务器B的mysql:
/etc/init.d/mysqld restart
5.5 进入数据库查看服务器A、B作为主服务器的状态
Ø服务器A:进入数据库
mysql -u root -p123456
查看服务器A作为主服务器的状态:
show master status;
Ø服务器B:进入数据库
mysql -u root -p123456
查看服务器B作为主服务器的状态:
show master status;
5.6 分别在两个服务器上设置并启动slave
Ø服务器A:进入数据库设置slave参数,其中master_user和master_password为在服务器B上面设置的同步账号的名称和密码;master_host为服务器B的IP地址;master_log_file和master_log_pos为服务器B中查看作为主服务器状态时显示的File和Position;
change master to master_user='tongbu',
master_password='tongbu',
master_host='10.1.1.2',
master_port=3306,
master_log_file='mysql-bin.000001',
master_log_pos=106;
Ø启动slave进程:
start slave;
Ø服务器B上的slave设置与服务器A相同,只是change master命令中的master属性均为服务器A。
Ø查看slave状态,其中Slave_IO_Running和Slave_SQL_Running均为Yes即说明同步启动成功。
show slave status\G;
Ø在服务器B上查看slave进程,检查其状态,看到Slave_IO_Running和Slave_SQL_Running均为Yes,至此双主同步配置成功。在两台服务器的zabbix库中任意添加数据,都可以同步到对端服务器上。
Ø注意:
l如果出现Slave_IO_Running: No或启动slave出现Could not initialize master info structure;的错误,分别在两个服务器上重新设置并启动slave。
stop slave;
reset slave;
l如果出现Last_IO_Error: error connecting to master 'tongbu@10.1.1.2:3306' -retry-time: 30 retries: 86400的错误,请检查防火墙配置。
Ø在mysql中可通过以下命令来查看主从状态
l查看master状态
show master status;
l查看slave状态
show slave status;
l查看当前进程
show processlist G;
l停止slave进程
stop slave;
l开始slave进程
start slave;
l重置slave进程
reset slave;
-
安装heartbear&pacemaker
Ø系统环境:CentOS5.6 32bit
注意:CentOS6.x和RHEL6.x请使用cman&pacemaker的模式创建集群。
6.1 概念组成及工作原理
6.1.1 heartbeat的概念
ØHeartbeat是Linux-HA项目中的一个组件,也是目前开源HA项目中最成功的一个例子, Linux-HA的全称是High-Availability Linux,这个开源项目的目标是:通过社区开发者的共同努力,提供一个增强linux可靠性(reliability)、可用性(availability)和可服务性(serviceability)(RAS)的群集解决方案。
ØHeartbeat提供了所有 HA 软件所需要的基本功能,比如心跳检测和资源接管、监测群集中的系统服务、在群集中的节点间转移共享 IP 地址的所有者等。
ØLinux-HA的官方网站: http://www.linux-ha.org
http://hg.linux-ha.org
6.1.2 HA集群相关术语
(1)节点(node)
运行heartbeat进程的一个独立主机,称为节点,节点是HA的核心组成部分,每个节点上运行着操作系统和heartbeat软件服务,在heartbeat集群中,节点有主次之分,分别称为主节点和备用/备份节点,每个节点拥有唯一的主机名,并且拥有属于自己的一组资源,主节点上一般运行着一个或多个应用服务。而备用节点一般处于监控状态。
(2)资源(resource)
资源是一个节点可以控制的实体,并且当节点发生故障时,这些资源能够被其它节点接管,heartbeat中,可以当做资源的实体有:
磁盘分区、文件系统、IP地址、应用程序服务、NFS文件系统
(3)事件(event)
也就是集群中可能发生的事情,例如节点系统故障、网络连通故障、网卡故障、应用程序故障等。这些事件都会导致节点的资源发生转移,HA的测试也是基于这些事件来进行的。
(4)动作(action)
事件发生时HA的响应方式,动作是由shell脚步控制的,例如,当某个节点发生故障后,备份节点将通过事先设定好的执行脚本进行服务的关闭或启动。进而接管故障节点的资源。
6.1.3 Heartbeat的组成
(1) Heartbeat的结构
Heartbeat1.x和2.0.x版本的结构十分简单,各个模块都集中在heartbeat中,到了3.0版本后,整个heartbeat项目进行了拆分,分为不同的项目来分别进行开发。
Heartbeat2.0.x之前的版本具有的模块:
heartbeat: 节点间通信检测模块ü
ha-logd: 集群事件日志服务ü
CCM(Consensus ClusterMembership):集群成员一致性管理模块ü
LRM (Local ResourceManager):本地资源管理模块ü
Stonith Daemon: 使出现问题的节点从集群环境中脱离ü
CRM(Cluster resourcemanagement):集群资源管理模块ü
Cluster policy engine: 集群策略引擎ü
Cluster transition engine:集群转移引擎ü
Heartbeat3.0拆分之后的组成部分:
Heartbeat:将原来的消息通信层独立为heartbeat项目,新的heartbeat只负责维护集群各节点的信息以及它们之前通信;
Cluster Glue:相当于一个中间层,它用来将heartbeat和pacemaker关联起来,主要包含2个部分,即为LRM和STONITH。
Resource Agent:用来控制服务启停,监控服务状态的脚本集合,这些脚本将被LRM调用从而实现各种资源启动、停止、监控等等。
Pacemaker:也就是Cluster Resource Manager (简称CRM),用来管理整个HA的控制中心,客户端通过pacemaker来配置管理监控整个集群。
Pacemaker 提供了多种用户管理接口,分别如下:
1)crm shell:基于字符的管理方式;
2)一个使用Ajax Web配置方式的web konsole窗口;
3)hb_gui ,即heartbeat的gui图形配置工具,这也是原来2.1.x的默认GUI配置工具;
4)DRBD-MC,一个基于Java的配置管理工具。
(2) Pacemaker内部组成及与各模块之间关系
(3) Heartbeat3.x内部组成及之间关系
(4) Heartbeat各个版本之间的异同
与1.x风格相比,Heartbeat2.1.x版本之后功能变化如下:
1)保留原有所有功能
如,网络,heartbeat ,机器down时均可切换资源。
2)自动监控资源
默认情况下每2分钟检测资源运行情况,如果发现资源不在,则尝试启动资源,如果60s后还未启动成功,则资源切换向另节点。时间可以修改。
3) 可以对各资源组实现独立监控.
比如apache运行在node1上,tomcat运行在node2上,Heartbeat可同时实现两台主机的服务监控。
4)同时监控系统负载
可以自动将资源切换到负载低的node上。
Heartbeat官 方最后一个STABLE release 2.x 版本是2.1.4,Heartbeat 3官方正式发布的首个版本是3.0.2,Heartbeat 3与Heartbeat2.x的最大差别在于,Heartbeat3.x按模块把的原来Heartbeat2.x拆分为多个子项目,但是HA实现原理与 Heartbeat2.x基本相同。配置也基本一致。
(5) Heartbeat集群的一般拓扑图
参考文献:http://ixdba.blog.51cto.com/2895551/745228
6.2 安装heartbeat
Ø卸载rpmforge-release-0.5.3-1.el5.rf
rpm -e rpmforge-release-0.5.3-1.el5.rf
备注:清除rpmforge源后才可安装heartbeat,否则会有冲突。
Ø安装epel-release-5-4.noarch.rpm
rpm -ivh epel-release-5-4.noarch.rpm
Ø导入key:
rpm --import /etc/pki/rpm-gpg/RPM-GPG-KEY-EPEL
Ø添加Cluster Labs repo:
wget -O /etc/yum.repos.d/pacemaker.repo http://clusterlabs.org/rpm/epel-5/clusterlabs.repo
Ø清除yum缓存:
yum clean all
Ø安装heartbeat:
yum install -y pacemaker corosync heartbeat
6.3 配置heartbeat
6.3.1 主配置文件(/etc/ha.d/ha.cf)
Ø注意:heartbeat安装后,3个配置文件默认存放在/usr/share/doc/heartbeat-3.0.3/目录中,需将其拷贝至/etc/ha.d/目录中。
cp /usr/share/doc/heartbeat-3.0.3/ha.cf /etc/ha.d/
cp /usr/share/doc/heartbeat-3.0.3/haresources /etc/ha.d/
cp /usr/share/doc/heartbeat-3.0.3/authkeys /etc/ha.d/
Ø配置主配置文件:
vi /etc/ha.d/ha.cf
下面对ha.cf文件的每个选项进行详细介绍,其中“#”号后面的内容是对选项的注释说明。
#debugfile /var/log/ha-debug
logfile /var/log/ha-log #指名heartbeat的日志存放位置。
#crm on #是否开启ClusterResourceManager(集群资源管理)功能。
bcast eth1 #指明心跳方式使用以太广播方式,并且是在eth1接口上进行广播。
keepalive 2 #指定心跳间隔时间为2秒(即每两秒钟在eth1上发送一次广播)。
deadtime30 #指定备用节点在30秒内没有收到主节点的心跳信号后,则立即接管主节点的服务资源。
warntime10 #指定心跳延迟的时间为十秒。当10秒钟内备份节点不能接收到主节点的心跳信号时,就会往日志中写入一个警告日志,但此时不会切换服务。
initdead120 #在某些系统上,系统启动或重启之后需要经过一段时间网络才能正常工作,该选项用于解决这种情况产生的时间间隔。取值至少为deadtime的两倍。
ucasteth0 192.168.8.73 #使用网卡eth0的udp单播来通知心跳
udpport 694 #设置广播通信使用的端口,694为默认使用的端口号。
baud 19200 #设置串行通信的波特率。
#serial/dev/ttyS0 #选择串行通信设备,用于双机使用串口线连接的情况。如果双机使用以太网连接,则应该关闭该选项。
auto_failbackoff #用 来定义当主节点恢复后,是否将服务自动切回,heartbeat的两台主机分别为主节点和备份节点。主节点在正常情况下占用资源并运行所有的服务,遇到故 障时把资源交给备份节点并由备份节点运行服务。在该选项设为on的情况下,一旦主节点恢复运行,则自动获取资源并取代备份节点,如果该选项设置为off, 那么当主节点恢复后,将变为备份节点,而原来的备份节点成为主节点。
#stonith baytech /etc/ha.d/conf/stonith.baytech # stonith的主要作用是使出现问题的节点从集群环境中脱离,进而释放集群资源,避免两个节点争用一个资源的情形发生。保证共享数据的安全性和完整性。
#watchdog/dev/watchdog #该选项是可选配置,是通过Heartbeat来监控系统的运行状态。使用该 特性,需要在内核中载入"softdog"内核模块,用来生成实际的设备文件,如果系统中没有这个内核模块,就需要指定此模块,重新编译内核。编译完成输 入"insmod softdog"加载该模块。然后输入"grepmisc /proc/devices"(应为10),输入"cat /proc/misc |grepwatchdog"(应为130)。最后,生成设备文件:"mknod /dev/watchdog c10130" 。即可使用此功能。
node node1 #主节点主机名,可以通过命令“uanme -n”查看。
node node2 #备用节点主机名。
ping192.168.8.1 #选择ping的节点,ping 节点选择的越好,HA集群就越强壮,可以选择固定的路由器作为ping节点,但是最好不要选择集群中的成员作为ping节点,ping节点仅仅用来测试网络连接。
respawnhacluster /usr/lib/heartbeat/ipfail #该 选项是可选配置,列出与heartbeat一起启动和关闭的进程,该进程一般是和heartbeat集成的插件,这些进程遇到故障可以自动重新启动。最常 用的进程是ipfail,此进程用于检测和处理网络故障,需要配合ping语句指定的ping node来检测网络的连通性。其中hacluster表示启动ipfail进程的身份。
检查配置:
egrep -v '^$|^#' /etc/ha.d/ha.cf
保证ipfail的可执行属性
chmod +x /usr/lib/heartbeat/ipfail
6.3.2 资源文件(/etc/ha.d/haresources)
ØHaresources文件用于指定双机系统的主节点、集群IP、子网掩码、广播地址以及启动的服务等集群资源,文件每一行可以包含一个或多个资源脚本名,资源之间使用空格隔开,参数之间使用两个冒号隔开,在两个HA节点上该文件必须完全一致,此文件的一般格式为:
node-name network <resource-group>
node-name表示主节点的主机名,必须和ha.cf文件中指定的节点名一致,network用于设定集群的IP地址、子网掩码、网络设备标识等,需要注意的是,这里指定的IP地址就是集群对外服务的IP地址,resource-group用来指定需要heartbeat托管的服务,也就是这些服务可以由heartbeat来启动和关闭,如果要托管这些服务,必须将服务写成可以通过start/stop来启动和关闭的脚本,然后放到/etc/init.d/或者/etc/ha.d/resource.d/目录下,heartbeat会根据脚本的名称自动去/etc/init.d或者/etc/ha.d/resource.d/目录下找到相应脚本进行启动或关闭操作。
Ø下面对配置方法进行具体说明:
vi /etc/ha.d/haresources
末尾添加:
server01 IPaddr::192.168.8.89/24/eth0 httpd zabbix_server
其中,zabbix是HA集群的主节点,heartbeat首先将执行/etc/ha.d/resource.d/192.168.8.89/24 start的操作,也就是虚拟出一个子网掩码为255.255.255.0,IP为192.168.8.89的地址,此IP为heartbeat对外提供服务的网络地址,同时指定此IP使用的网络接口为eth0,接着启动apache和zabbix_server服务。
注意:主节点和备份节点中资源文件haresources要完全一样。
6.3.3 认证文件(/etc/ha.d/authkeys)
Øauthkeys文件用于设定heartbeat的认证方式,共有三种可用的认证方式:crc、md5和sha1,三种认证方式的安全性依次提高,但是占用的系统资源也依次增加。如果heartbeat集群运行在安全的网络上,可以使用crc方式,如果HA每个节点的硬件配置很高,建议使用sha1,这种认证方式安全级别最高,如果是处于网络安全和系统资源之间,可以使用md5认证方式。这里我们使用crc认证方式,设置如下:
vi /etc/ha.d/authkeys
修改:
auth 1
1 crc
#2 sha1 HI!
#3 md5 Hello!
需要说明的一点是:无论auth后面指定的是什么数字,在下一行必须作为关键字再次出现,例如指定了“auth 1”,下面一定要有一行“1 认证类型”。
注意:最后确保这个文件的权限是600(即-rw-------),否则heartbeat将无法启动。
chmod 600 /etc/ha.d/authkeys
6.3.4 配置备用节点的heartbeat
Ø在备用节点上也需要安装heartbeat,安装方式与在主节点安装过程一模一样。安装完毕,在备用节点上使用scp命令把主节点配置文件传输到备份节点。
scp -r 192.168.8.73:/etc/ha.d/* /etc/ha.d/
注意:修改主配置文件ha.cf中的目标服务器为ucast eth0192.168.8.74
vi /etc/ha.d/ha.cf
修改:
ucast eth0 192.168.8.74
6.4 启动heartbeat
Ø修改heartbeat目录权限,可以用以下命令:
find / -type d -name "heartbeat" -exec chown -R hacluster {} \;
find / -type d -name "heartbeat" -exec chgrp -R haclient {} \;
Ø设置环境变量,增加在/etc/profile最后:
vi /etc/profile
添加:
export OCF_ROOT=/usr/lib/ocf
执行source命令:
source /etc/profile
Ø启动heartbeat:
/etc/init.d/heartbeat start
6.5 配置crm
Ø禁用stonith:
crm configure property stonith-enabled=false
Ø添加ClusterIP、apache和zabbix server
crm configure primitive ClusterIP ocf:heartbeat:IPaddr2 params ip=192.168.8.89 cidr_netmask=24 op monitor interval="20s"
crm configure primitive WebSite lsb:httpd op start interval="0s" timeout="120s" op monitor interval="20s" timeout="20s" meta migration-threshold="1" failure-timeout="60s"
crm configure primitive Zabbix-HA lsb:zabbix_server op start interval="0s" timeout="120s" op monitor interval="20s" timeout="20s" meta migration-threshold="1" failure-timeout="60s"
备注:以上是采用lsb的方式来管理apache,即/etc/init.d/httpd启动脚本。如需使用ocf来管理,则进行如下配置,开启 Apachestatus URL
vi /etc/httpd/conf/httpd.conf
去除以下内容的注释:
<Location /server-status>
SetHandler server-status
Order deny,allow
Deny from all
Allow from 127.0.0.1
</Location>
添加apache资源的命令则为:
crm configure primitive WebSite ocf:heartbeat:apache params configfile=/etc/httpd/conf/httpd.conf statusurl="http://localhost/server-status" op monitor interval=20s
Ø忽略节点的法定人数策略:
crm configure property no-quorum-policy=ignore
Ø防止资源在节点恢复后移动,缺省为0:
crm configure rsc_defaults resource-stickiness=100
Ø设置apache,zabbix server,virtual ip为一个group:
crm configure group certusGroup ClusterIP WebSite Zabbix-HA
备注:certusGroup是自定义的组名id,ClusterIP WebSiteZabbix-HA则是要放到certusGroup组中的资源,这里是有序的,三者依次执行。ClusterIP将优先于WebSiteZabbix-HA执行。
Ø强制保证资源启动停止顺序:
crm configure order apache-after-ip mandatory: ClusterIP WebSite
Ø添加新资源pingd:(ping 192.168.8.1,用于代替ipfail)
crm configure primitive clusterPingd ocf:heartbeat:pingd params host_list=192.168.8.1 multiplier=100
Ø添加pingd的clone:
crm configure clone clusterPingdclone clusterPingd meta globally-unique=false
Ø与ClusterIP绑定:(ClusterIP运行的节点一定要有pingd运行)
crm configure location my_app_on_connected_node ClusterIP rule -inf: not_defined pingd or pingd lte 0
Ø查询状态:
Ø验证配置文件是否正确:
crm_verify -L -V
Ø以上内容在二个节点做相同配置,如果配置错误可以参考crm命令修改。也可以停止heartbeat服务,删除/var/lib/heartbeat/crm/目录下的所有文件后重新配置:
/etc/init.d/heartbeat stop
rm -f /var/lib/heartbeat/crm/*
/etc/init.d/heartbeat start
官方参考文档:
http://clusterlabs.org/doc/zh-CN/Pacemaker/1.1-crmsh/html/Clusters_from_Scratch/index.html
6.5.1 附录一、crm常用命令参考
Ø查询crm状态:
crm status
Ø移动资源:
crm resource move
备注:在server02上将资源从server01中移动过来。适合的场景:server01需下线维护等类似的情况。
示例:
crm resource move WebSite server02
Ø取消资源移动:
crm resource unmove WebSite
Ø参考完整配置:
crm configure show
Ø修改某个配置:
crm configure edit WebSite
Ø启动、停止资源:
crm resource start WebSite
crm resource stop WebSite
Ø删除资源:
crm configure delete WebSite
Ø更多内容请使用help命令或参考官方文档:
crm help
6.5.2 附录二、安装过程中异常处理
Øcrm configure show 可能报告出错,需强制升级crm。
cibadmin --upgrade --force
6.6 故障模拟
Ø方案1:
l通过命令停止server01网卡或者停止heartbeat
ifdown eth1
or:
/etc/init.d/heartbeat stop
l观察server02的系统日志确认server01节点已经丢失:
lserver02接替并启动相关应用:
l检查server02上crm的状态:
lserver02已成功接替应用。
Ø方案2:关闭server01服务器,略等几秒,检查server02上crm的状态。
6.7 防火墙设置
iptables -A INPUT -p udp --dport 694 -j ACCEPT
- 安装cman&pacemaker
Ø系统环境:RHEL6.2 64bit
注意:CentOS5.x和RHEL5.x请使用heartbeat&pacemaker的模式创建集群。
7.1 简介
Ø参考了较多国内外文献了解到,从CentOS6.x和RHEL6.x起,yum安装pacemaker的版本为1.1.8或以上,且移除了crm(即crmsh,集群资源管理)。pacemaker与rhcs(红帽的集群系统)的组件MGmanager的资源和fence组件(resource & fencepackage)的管理合并到一起去了。至于原因,可参考官方申明:
Installing on RHEL-6
Pacemaker has been available as part of RHEL since 6.0 as part of the High Availability (HA) add-on.
While this is an important step, it has created somechallenges, because:
- Red Hat funds much of Pacemaker's development, so weprefer to make packages available via their official channels rather than thecommunity site
- Pacemaker is currently listed as Tech Preview (TP) andtherefor unsupported by Red Hat
- The HA add-on costs money
Why should I pay for something if I still wont besupported?
Valid question,but there are still plenty of other software (such as corosync openais, cman,and fencing agents) that is supported if you buy the add-on. You also get awarm fuzzy feeling for supporting continued Pacemaker development.
Even if the lackof support is a deal breaker, consider buying at least one copy of the add-on.You'll get software updates for the entire stack and it helps Red Hat gauge thedemand for Pacemaker - which could conceivably help it become supported sooner.
When Community Support is Enough
If you're reallynot interested in support, you have a number of options available:
- Install from the RHEL install media
- Install from the CentOS or Scientific Linuxrepos
- Download and rebuild the necessary SRPMsfrom the Red Hat FTP server
http://clusterlabs.org/wiki/Install#Binary_Packages
Ø如果不习惯使用pcs对pacemaker进行管理,可以从opensuse.org库中下载到crmsh。
wget -O /etc/yum.repos.d/ha-clustering.repo http://download.opensuse.org/repositories/network:/ha-clustering/RedHat_RHEL-6/network:ha-clustering.repo
yum install -y crmsh
参考此站点,可以获取更多crmsh的信息:
http://lists.linux-ha.org/pipermail/linux-ha-dev/2012-October/019626.html
Ø如果不习惯cman&pacemaker的架构,可以参考以下文献实现heartbear&pacemaker的模式。
ülinux-ha heartbeat 搭建
http://space.itpub.net/133735/viewspace-731951
üCoroSync/Pacemaker on Centos 6
http://snozberry.org/blog/2012/05/02/corosync-slash-pacemaker-on-centos-6/
üHeartbeat3.x应用全攻略之:安装、配置、维护
http://ixdba.blog.51cto.com/2895551/746271
7.2 安装cman
Ø安装cman和相关依赖包:
yum install -y pacemaker cman ccs resource-agents pcs
备注:至此RHEL6.x已可以删除CentOS6源
rm -f /etc/yum.repos.d/CentOS6-Base-163.repo
Ø安装crmsh(可选):
wget -O /etc/yum.repos.d/ha-clustering.repo http://download.opensuse.org/repositories/network:/ha-clustering/RedHat_RHEL-6/network:ha-clustering.repo
yum install -y crmsh
rm -f /etc/yum.repos.d/ha-clustering.repo
注意:network:ha-clustering源中pacemaker和相关依赖包的版本为1.1.9,因时间关系未做详细测试,故此步骤不可执行在“安装cman和相关依赖包”之前。
7.3 配置cman
Ø创建集群名称和节点:
ccs -f /etc/cluster/cluster.conf --createcluster certusnet
注意:名称可以自定义,但不能超过15个字符。此例中使用的名称为certusnet。
ccs -f /etc/cluster/cluster.conf --addnode server01
ccs -f /etc/cluster/cluster.conf --addnode server02
Ø验证配置文件是否正确:
ccs_config_validate -f /etc/cluster/cluster.conf
Øteach CMAN how to send it's fencing requests to Pacemaker.(不知道如何翻译会比较合适,就引用原文吧)
ccs -f /etc/cluster/cluster.conf --addfencedev pcmk agent=fence_pcmk
ccs -f /etc/cluster/cluster.conf --addmethod pcmk-redirect server01
ccs -f /etc/cluster/cluster.conf --addmethod pcmk-redirect server02
ccs -f /etc/cluster/cluster.conf --addfenceinst pcmk server01 pcmk-redirect port=server01
ccs -f /etc/cluster/cluster.conf --addfenceinst pcmk server02 pcmk-redirect port=server02
Ø拷贝配置文件至server02节点:
scp /etc/cluster/cluster.conf server02:/etc/cluster/
备注:如果配置错误或者更改,可以停止cman服务并在各节点删除主配置文件/etc/cluster/cluster.conf后重新配置。
/etc/init.d/cman stop
rm -f /etc/cluster/cluster.conf
/etc/init.d/cman start
7.4 启动集群
Ø配置集群不需要法定人数可以开启:
echo "CMAN_QUORUM_TIMEOUT=0" >> /etc/sysconfig/cman
Ø修改/etc/hosts否则集群将无法启动:
vi /etc/hosts
注销以下内容:
127.0.0.1 localhost.localdomain localhost.localdomain localhost4 localhost4.localdomain4 localhost server02
::1 localhost.localdomain localhost.localdomain localhost6 localhost6.localdomain6 localhost server02
Ø配置cman和pacemaker随系统启动:
chkconfig cman on
chkconfig pacemaker on
Ø启动cman和pacemaker:
/etc/init.d/cman start
/etc/init.d/pacemaker start
7.5 配置pcs
Ø禁用stonith:
pcs property set stonith-enabled=false
Ø添加ClusterIP、apache和zabbix server
pcs resource create ClusterIP ocf:heartbeat:IPaddr2 ip=192.168.8.89 cidr_netmask=24 op monitor interval=20s
pcs resource create WebSite lsb:httpd op monitor interval=20s
pcs resource create Zabbix-HA lsb:zabbix_server op monitor interval=20s
备注:以上是采用lsb的方式来管理apache,即/etc/init.d/httpd启动脚本。如需使用ocf来管理,则进行如下配置,开启 Apachestatus URL
vi /etc/httpd/conf/httpd.conf
在以上内容后追加:
<Location /server-status>
SetHandler server-status
Order deny,allow
Deny from all
Allow from 127.0.0.1
</Location>
添加apache资源的命令则为:
pcs resource create WebSite ocf:heartbeat:apache configfile=/etc/httpd/conf/httpd.conf statusurl="http://localhost/server-status" op monitor interval=20s
Ø忽略节点的法定人数策略:
pcs property set no-quorum-policy=ignore
Ø设置apache,zabbix server,virtual ip为一个group:
pcs resource group add certusGroup ClusterIP WebSite Zabbix-HA
备注:certusGroup是自定义的组名id,ClusterIP WebSiteZabbix-HA则是要放到certusGroup组中的资源,这里是有序的,三者依次执行。ClusterIP将优先于WebSiteZabbix-HA执行。
Ø强制保证资源启动停止顺序:
pcs constraint order ClusterIP then WebSite
Ø防止资源在节点恢复后移动,缺省为0:
pcs resource rsc defaults resource-stickiness=100
Ø查询状态:
pcs status
Ø验证配置文件是否正确:
crm_verify -L -V
Ø以上内容只需要在一个节点进行配置,如果配置错误可以参考pcs命令修改。也可以停止pacemaker服务,删除/var/lib/pacemaker/cib/目录下的所有文件后重新配置:
/etc/init.d/pacemaker stop
rm -f /var/lib/pacemaker/cib/*
/etc/init.d/pacemaker start
官方参考文档:
http://clusterlabs.org/quickstart-redhat.html
http://clusterlabs.org/doc/zh-CN/Pacemaker/1.1-pcs/html/Clusters_from_Scratch/index.html
7.5.1 附录一、pcs常用命令参考
Ø查询 crm 状态:
pcs status
Ø移动资源:
pcs resource move
备注:在server02 上将资源从server01 中移动过来。适合的场景:server01 需下线维护等类似的情况。
示例:
pcs resource move WebSite server02
Ø取消资源移动:
pcs resource unmove WebSite
Ø参考完整配置:
pcs config
Ø修改某个配置:
pcs resource update WebSite
Ø启动、停止资源:
pcs resource start WebSite
pcs resource stop WebSite
Ø删除资源:
pcs resource delete WebSite
Ø更多内容请使用 help 命令或参考官方文档:
pcs help
7.6 故障模拟
Ø方案1:
l通过命令停止server01网卡或者停止pacemaker和cman服务:
ifdown eth0
or:
/etc/init.d/pacemaker stop
/etc/init.d/cman stop
l观察server02的系统日志确认server01节点已经丢失:
lserver02接替并启动相关应用:
l检查server02上pcs的状态:
lserver02已成功接替应用。
Ø方案2:关闭server01服务器,略等几秒,检查server02上pcs的状态。
7.7 防火墙设置
iptables -A INPUT -p udp --dport 5404 -j ACCEPT
iptables -A INPUT -p udp --dport 5405 -j ACCEPT
- 防火墙设置
Ø清除所有规则:
iptables -F
Ø接纳属於现存及相关连接的压缩:
iptables -A INPUT -m state --state ESTABLISHED,RELATED -j ACCEPT
Ø设置INPUT、FORWARD、及OUTPUT链的缺省策略:
iptables -P INPUT DROP
iptables -P FORWARD DROP
iptables -P OUTPUT ACCEPT
Ø设置localhost的访问权:
iptables -A INPUT -i lo -j ACCEPT
Øtraceroute探测解决:
iptables -A INPUT -p icmp --icmp-type 11 -j DROP
ØICMP timestamp请求响应漏洞解决:
iptables -A INPUT -p icmp --icmp-type timestamp-request -j DROP
iptables -A OUTPUT -p icmp --icmp-type timestamp-reply -j DROP
Ø允许ping:
iptables -A INPUT -p icmp --icmp-type 8 -j ACCEPT
iptables -A OUTPUT -p icmp --icmp-type 0 -j ACCEPT
Øssh端口:
iptables -A INPUT -p tcp --dport 22 -j ACCEPT
Ødns:
iptables -A INPUT -p tcp --sport 53 -j ACCEPT
iptables -A INPUT -p udp --sport 53 -j ACCEPT
Øheartbeat:
iptables -A INPUT -p udp --dport 694 -j ACCEPT
备注:此为heartbeat的健康检查通讯端口,cman不用添加
Øntp:
iptables -A INPUT -p udp --sport 123 -j ACCEPT
Øapache:
iptables -A INPUT -p tcp --dport 80 -j ACCEPT
Ømysql:
iptables -A INPUT -p tcp --dport 3306 -j ACCEPT
Øcman:
iptables -A INPUT -p udp --dport 5404 -j ACCEPT
iptables -A INPUT -p udp --dport 5405 -j ACCEPT
备注:此为cman的健康检查通讯端口,heartbeat不用添加
Øzabbix server:
iptables -A INPUT -p tcp --dport 10050 -j ACCEPT
iptables -A INPUT -p tcp --dport 10051 -j ACCEPT
iptables -A INPUT -p udp --dport 10050 -j ACCEPT
iptables -A INPUT -p udp --dport 10051 -j ACCEPT
Ø保存防火墙设置:
/etc/init.d/iptables save
- 脚本安装和卸载zabbix
9.1 脚本安装zabbix server
说明:
Ø脚本执行前请根据实际环境修改变量;
Ø将zabbix_install目录及目录中epel-release-5-4.noarch.rpm、epel-release-6-8.noarch.rpm、msyh.ttf和zabbix_server_install(ha).sh一并上传至主备节点服务器的/root目录中;
Ø脚本执行过程中会自动判断操作系统版本是RHEL5.x或6.x、CentOS5.x或6.x、主/备服务器、以及是32位或是64位系统,并安装相应的软件包和修改配置。
Ø脚本安装完毕后打开浏览器,输入http://IP/zabbix/,就会出现WEB界面安装向导,按向导提示完成zabbix安装。请参考4.6.9节中截图的相关内容。注意:在节点1完成配置后进行一次主备替换在节点2完成相同配置
脚本下载地址:http://down.51cto.com/data/834358
9.2 脚本卸载zabbix server
脚本下载地址:http://down.51cto.com/data/834358
因篇幅关系,后篇的链接为:
zabbix 安装使用手册(HA)-2
http://lan2003.blog.51cto.com/252098/1221314
全文下载地址:http://down.51cto.com/data/834358
lan2003 http://lan2003.blog.51cto.com/252098/1221149